Parallel Execution and Scheduling of QuNex commands
Contents
Parallel Execution and Scheduling of QuNex commands#
Parallelism in QuNex#
QuNex provides native support for parallel processing. To process multiple sessions in parallel use the parsessions parameter. Some commands also allow paralellism on a lower level, the level of individual elements within sessions, to process several of these elements in parallel use the parlements parameter. For example, with parelements you can process multiple BOLDs in hcp_fmri_volume of hcp_fmri_surface in parallel. If you are not using a scheduler, QuNex will execute everything sequentially by default (parsessions=1, parelements=1).
When using a scheduler, QuNex will by default create a separate job for each session in the study, inside each job everything will run sequentially. As a result all sessions will be processed in parallel as independent jobs. So, if you are using the scheduler and you do not provide the parjobs parameter in a study with 10 sessions QuNex would spawn 10 jobs.
If you are using the scheduler (via the schedule parameter) and want to fine tune QuNex's parallelism, you can also specify how many jobs you want QuNex to create through the parjobs parameter. QuNex will then automatically distribute sessions in your study over these jobs. How sessions get distributed also depends on the parsessions parameter. For example, if I schedule a QuNex command in a study with 10 sessions and set parjobs to 2 and parsessions to 5 then 5 sessions will be ran in parallel within the first spawned job and the other 5 within the second spawned job. If you do not provide the parsessions parameter then QuNex will distribute all of the sessions across spawned jobs uniformly and execute them in sequence inside each of the jobs. For example, if we have 13 sessions and set parjobs to 4, QuNex will create 4 jobs, 3 jobs will execute 3 sessions and 1 will execute 4 sessions in a sequential manner.
Note that the values of the scheduling parameters (parjobs, parsessions and parelements) are only setting the upper bounds for each level of parallelism. If I set parjobs to 5 and parsessions to 10 in a study that has only 2 sessions then QuNex will spawn a single job that will run both sessions in parallel. Furthermore, parjobs has higher priority then parsessions. For example, if my study has 10 sessions, and I set parjobs to 5 and parsessions to 4 then QuNex will spawn 5 jobs and distribute sessions between them evenly, as a result 2 sessions will be running inside each job. On that note, if parjobs is not set then parsession has no impact since a job will be spawned for each job.
With SLURM schedulers users can facilitate the extremely efficient and convenient functionality of SLURM job arrays. To use this option, you have to set the array option for SLURM, e.g. --scheduler="SLURM,array,cpus-per-task=4,time=48:00:00,mem-per-cpu=8000,jobname=surface". With job arrays the parsessions parameter is ignored and each session is assigned its own job within the array, parelements still determines the amount of elements that will run in parallel within a job.
Scheduler functionality overview#
Currently you can use the QuNex's internal scheduling implementation to schedule commands via three commonly used schedulers: SLURM and PBS. For more information about scheduling please consult the following resources:
In all three cases the scheduling is achieved via the schedule parameter. The schedule parameter should be a comma separated list of scheduler parameters. The first parameter has to be the scheduler name (PBS, SLURM) and the rest of the parameters are key=value pairs that are passed as settings to the scheduler. Key here represents a scheduler's parameter (or flag), while value represents the value that we want to set to that particular parameter. The three examples below provide an example for how to schedule the QuNex hcp_fmri_surface command via the supported schedulers.
If you wish to execute any bash commands on the compute node before the scheduled QuNex command, you can use the bash parameter. For example, setting --bash="module load CUDA/9.1.85" will first execute the module load command and then execute the scheduled QuNex command.
Note here that scheduler parameters that determine required computational resources (cpus-per-task in SLURM, nodes and ppn in PBS) are set automatically based on the defined parallelism (based on the parsessions and parelements parameters). If users are not satisfied with these automatically calculated defaults they can set the scheduler parameters manually.
SLURM#
qunex hcp_fmri_surface \
--sessionsfolder="/data/testStudy/sessions" \
--batchfile="/data/testStudy/processing/batch.txt" \
--overwrite="yes" \
--parsessions=2 \
--parelements=4 \
--scheduler="SLURM,cpus-per-task=8,time=48:00:00,mem-per-cpu=2000,jobname=surface"
PBS#
qunex hcp_fmri_surface \
--sessionsfolder="/data/testStudy/sessions" \
--batchfile="/data/testStudy/processing/batch.txt" \
--overwrite="yes" \
--parsessions=2 \
--parelements=4 \
--scheduler="PBS,nodes=1:ppn=4,walltime=48:00:00,mem=8gb,jobname=surface"
Scheduling details#
Besides the settings flags that are scheduler dependent, you can use the jobname and jobnum flags to define the final name of the scheduled job:
jobname- the name of the job to run [schedule],jobnum- the number of the job being run [1].
Note here that you can also set the name of the job by using scheduler specific flags (e.g., N for PBS, J for SLURM, etc.). The final name of the scheduled job is composed as <jobname>-#<jobnum>.
SLURM details#
For SLURM any provided key/value or parameter/value pair will be passed in the form: #SBATCH --<key>=<value>
Some of the possible keys/parameters to set are:
partition... The partition (queue) to usenodes... Total number of nodes to run oncpus-per-task... Number of cores per tasktime... Maximum wall time DD-HH:MM:SSconstraint... Specific node architecturemem-per-cpu... Memory requested per CPU in MBmail-user... Email address to send notifications tomail-type... On what events to send emails
PBS details#
PBS uses various flags to specify parameters. Be careful that the settings string includes only comma separated key=value pairs. Scheduler will then do its best to use the right flags. Specifically:
Keys: mem, walltime, software, file, procs, pmem, feature, host, naccesspolicy, epilogue, prologue will be submitted using: #PBS -l <key>=<value>.
Keys: j, m, o, S, a, A, M, q, t, e, N, l will be submitted using: #PBS -<key> <value>
Key: depend will be submitted using: #PBS -W depend=<value>
Key: umask will be submitted using: #PBS -W umask=<value>
Key: nodes is a special case. It will be submitted as: #PBS -l <value>
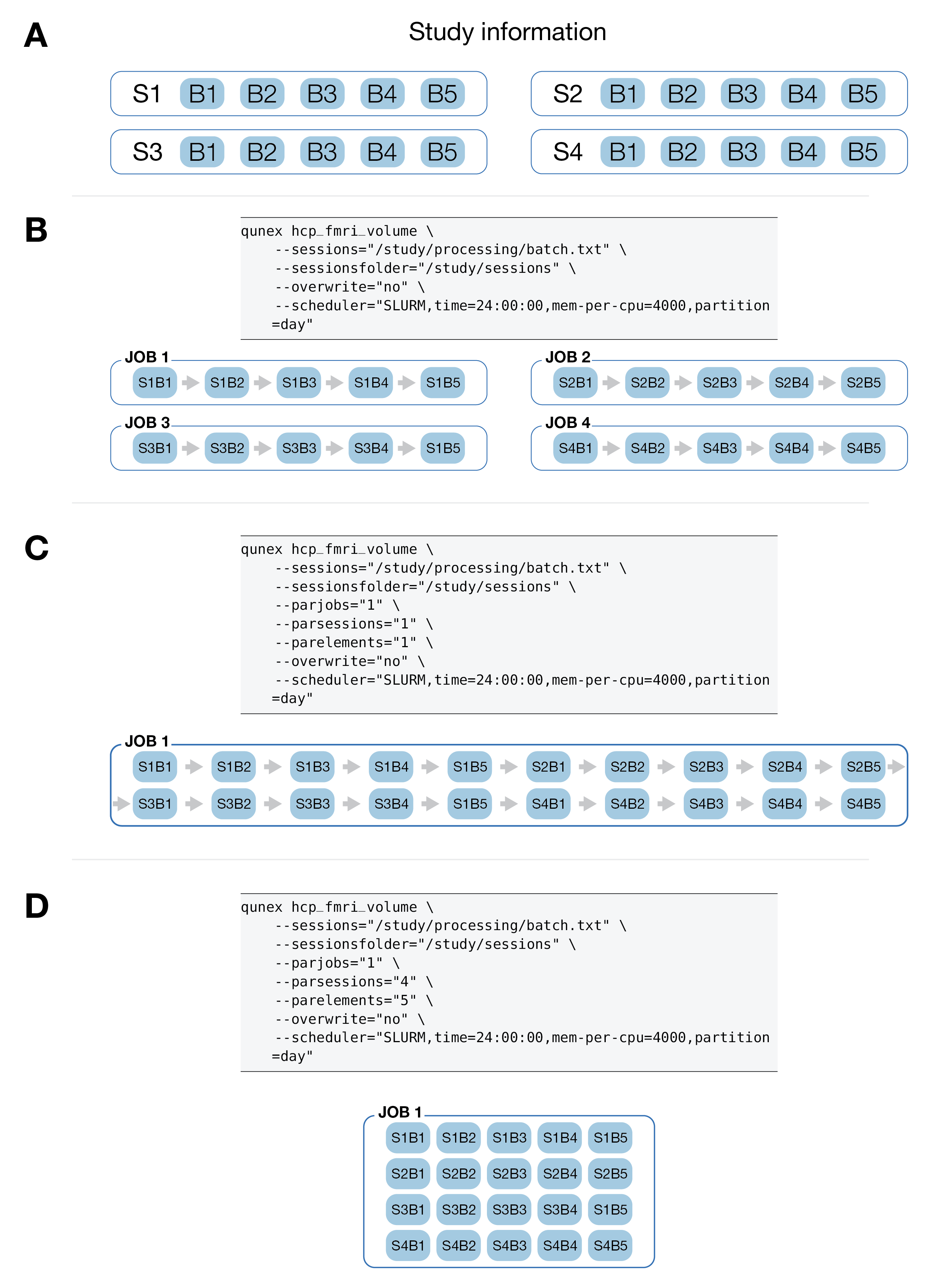
A Visualization of Parallelism and Scheduling in QuNex#
The figure below visualizes the parallelism and scheduling logic in QuNex. Panel A shows the study information, our sample study has 4 sessions and each session has 5 BOLDs. Panel B visualizes the default execution, QuNex will create an individual job for each session, within each sessions elements/BOLDs will run in a serial fashion. Panel C shows a completely serial execution, where all elements/BOLDs will be executed in a serial fashion within a single job. Panel D shows complete parallelism within a single job, where all elements/BOLDs will be executed in parallel.